Returning self or void suggests mutability
So there’s a blog post that advises every method should, when possible, return self. I’d like to suggest you do the opposite: wherever possible, return something other than self.
Mutation is hard
Configuration and scope
Most applications have configuration: how to open a connection to the database, what file to log to, the locations of key data files, etc.
Configuration is hard to express correctly. It’s dynamic because you don’t know the configuration at compile time–instead it comes from a file, the network, command arguments, etc. Config is almost always implicit, because it affects your functions without being passed in as an explicit parameter. Most languages address this in two ways:
Unsafe thread concurrency with fork
AWS::S3 is not threadsafe. Hell, it’s not even reusable; most methods go through a class constant. To use it in threaded code, it’s necessary to isolate S3 operations in memory. Fork to the rescue!
def s3(key, data, bucket, opts)
begin
fork_to do
AWS::S3::Base.establish_connection!(
:access_key_id => KEY,
:secret_access_key => SECRET
)
AWS::S3::S3Object.store key, data, bucket, opts
end
rescue Timeout::Error
raise SubprocessTimedOut
end
end
def fork_to(timeout = 4)
r, w, pid = nil, nil, nil
begin
# Open pipe
r, w = IO.pipe
# Start subprocess
pid = fork do
# Child
begin
r.close
val = begin
Timeout.timeout(timeout) do
# Run block
yield
end
rescue Exception => e
e
end
w.write Marshal.dump val
w.close
ensure
# YOU SHALL NOT PASS
# Skip at_exit handlers.
exit!
end
end
# Parent
w.close
Timeout.timeout(timeout) do
# Read value from pipe
begin
val = Marshal.load r.read
rescue ArgumentError => e
# Marshal data too short
# Subprocess likely exited without writing.
raise Timeout::Error
end
# Return or raise value from subprocess.
case val
when Exception
raise val
else
return val
end
end
ensure
if pid
Process.kill "TERM", pid rescue nil
Process.kill "KILL", pid rescue nil
Process.waitpid pid rescue nil
end
r.close rescue nil
w.close rescue nil
end
end
Tracking down requires
Sometimes you need to figure out where ruby code came from. For example, ActiveSupport showed up in our API and started breaking date handling and JSON. I could have used git bisect to find the commit that introduced the problem, but there’s a more direct way.
<cr:code lang=“ruby”> set_trace_func proc { |event, file, line, id, binding, classname| if id == :require args = binding.eval(“local_variables”).inject({}) do |vars, name| value = binding.eval name vars[name] = value unless value.nil? vars end
Monkeypatching is for wimps. Use set_trace_func.
Most Rubyists know about monkeypatching: opening up someone else’s class (often, something like String or Object) to modify some of its methods after the fact. It’s both incredibly powerful when used judiciously, and incredibly dangerous the rest of the time. I’ve spent countless hours trying to debug conflicting definitions of #to_json, or trying to untangle ActiveRecord’s astonishing levels of dynamic method aliasing.
I’m here to introduce you to a far more exciting threat: set_trace_func. This invidious callback is invoked on every function call and line of the Ruby interpreter. Most people, if they’re aware of it at all, correctly assume it’s intended for profiling.
Yamr: A Linux Yammer Client
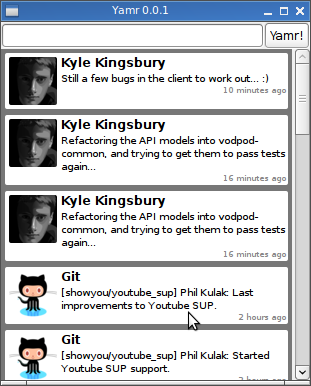
Sometime in the last couple of weeks, the Yammer AIR client stopped fetching new messages. I’ve grown to really like the service, especially since it delivers a running stream of commits to the Git repos I’m interested in, so I broke down and wrote my own client.
Cortex Reaver 0.2.0 Released
All right boys and girls, I’m all for quality releases and everything, but Cortex Reaver 0.2.0 is raring to go. Just gem upgrade to get some awesome blogging goodness.
New Vodpod API Bindings
I re-wrote the Ruby Vodpod bindings for the new API I’ve been writing. It’s available as a gem:
cr:codegem install vodpod</cr:code>
RSSCloud Callbacks to a Different IP
A bit of context, in case you haven’t been keeping up with the real-time web craze:
RSSCloud is an… idea* for getting updates on RSS feeds to clients faster, while decreasing network load. In traditional RSS models, subscribers make an HTTP request every 10 minutes or so to a publisher to check for updates. In RSSCloud, a cloud server aggregates several feeds from authors. When feeds are changed, their authors send an HTTP request to the cloud server notifying them of the update. The cloud server contacts one or more subscribers of the feed, sending them a notice that the feed has changed. The subscribers then request the feed from the authors. Everyone gets their updates faster, and with fewer requests across the network.
Cortex Reaver 0.2
I’ve been working a lot on Cortex Reaver lately, with several new features in the pipe. I’m using Vim for awesome syntax highlighting, refining the plugins/sidebar infrastructure, creating improved admin tools for long-running tasks (like rebuilding all the photo sizes) and fixing several bugs in the CRUD lifecycle. All that comes in a slick new visual style, including a new stylesheet/js compiler which makes page loads much faster (eliminating something like 20 external HTTP requests in the non-cached case). Finding time to really sit down and hack on CR has been tough lately with all the grad school/work stuff going on, but as new users are coming on board I’m motivated to keep improving.
Rails 2.3 JSON is a Broken Hack
Rails, what were you thinking? You went and wrote your own ridiculous JSON serializer in pure Ruby, when a perfectly good C-extension gem already does the job 20 times faster. What’s worse, you gave your to_json method (which clobbers every innocent object it can get its grubby little hands on) a completely incompatible method signature from the standard gem version. You just can’t mix the two, which is ALL KINDS OF FUN for those of us who need to push more than 10 reqs/sec.
Then there’s awesome behavior like this:
Construct 0.1.3
I released version 0.1.3 of Construct today. It incorporates a few bugfixes for nested schemas, and should be fit for general use.
Construct: Ruby Configuration
I got tired of writing configuration classes for everything I do, and packaged it all up in a tiny gem: Construct.
Highlights
Ruby Vodpod Bindings
I recently wrote some quick and dirty Ruby bindings for the Vodpod API. They’re pretty rough right now, but usable.
Cortex Reaver
I’ve migrated Aphyr.com off its old, dying hardware onto a spiffy new Linode. So far it’s going pretty well! My new blog engine, Cortex Reaver is also up and running.
Currently waiting for my flight to depart from PDX. The 15 inches of snow Nature dropped on us this week meant long waits for most people, but I was able to get through ticketing and security in about half an hour, and the MAX got me here just fine (though we passed a couple jacknifed semis on the way). Now all I have to do is make my connection through SeaTac in an hour. That… could be interesting.
IRC Client
I got distracted from writing my backup system and started an IRC client… argh, why are the interesting problems so hard to stop working on? I essentially wasted my whole weekend on this.
On the other hand, it’s pretty cool. :D
Process Monitoring with Ruby
It looks like there’s a catastrophic memory leak in the Rails app I wrote last summer, and in trying to track it down, I needed a way to look at process memory use over time. So, I put together this little library, LinuxProcess, which uses the proc filesystem to make it easier to monitor processes with Ruby. Enjoy!
Updates to Sequenceable
I’ve updated Sequenceable with new code supporting restriction of sequences to subsets through some sneaky SQL merging, ellipsized pagination (“1 … 4, 5, 6 … 10”), and proper handling of multiple sort columns.
Performance issues
Ruby on Rails is much, much, slower than I would like. It takes around .25 seconds to render the index page: about 10 times longer than Ragnar. I've alleviated the problem somewhat by switching to a Mongrel cluster with Apache's mod-balancer, but performance is still slow. I can't add any more foreign key constraints--pretty much every feasible relationship is locked down. I guess it's just down to ActiveRecord tuning, and figuring out how to make ERB run with any semblance of speed. Possibly memcached, too...
Anyway, sorry for the inexplicable downtime. Things are still moving around quite a bit.
New Features, SSH Completion, and the Dangers of Overloading the Core Library
Added ATOM feeds for journals, photographs, and a combined feed. Also added EXIF support to photographs, such that files with EXIF headers (those from about the last year or so) display some shot information as well.
Also, I caught bash programmable completion completing paths on remote servers over SSH. I was copying a file from the laptop to the server, hit tab to complete the directory on the server side... and it worked. That was quite surprising, when I realized that my ordinarily useless request had actually been carried out. Hurrah for bash making my life easier.
You Win, Ruby
After the last three months, I've come to the conclusion: Ruby is a wonderful language, and I don't want to write code in Perl any more. I like Perl: it's fast, powerful, and has a terrific community around it. If you wanted to run your television through a LEGO USB IR transceiver, yeah, there's probably something in CPAN for that. However, I'm finding that the rocky syntax of Perl gets in the way of my thinking. I don't want to use $hash_of_hashes->{'key'}->{'key2'} to get at at what should be a simple data structure. Using five special characters on a variable makes my code hard to understand, and makes it easier to cause bugs. It's a good language, but Perl has its limits. After spending months writing clean, joyful code, I think that the Ruby language maps more closely to the domains of the problems I'm trying to solve.
There are a lot of things I like very much about Ragnar: it's quite fast, extensively configurable, and compliant with web standards by design. XSLT transforms keep logic and presentation well separated, and the powerful query engine makes node-level logic simple. I plan to preserve the best aspects of this design, but refactor the code into a Ruby platform, separate node data taipus into a more traditional database schema for efficiency, and define a plugin architecture with callbacks for node lifecycle handling. For now, at least, I'll avoid the temptation to use Rails for this project: I prefer XSLT, and working this way is more fun for me. :-)
Interactive Ruby Interpreter
Why the Lucky Stiff (author of Why's Poignant Guide to Ruby) has written a slick web frontend to the IRB Ruby shell, allowing anyone to try out the Ruby language from their browser. There's also a handy tutorial available.
Work
So I'm back at work again, but my job has changed. No longer am I the stealthy IT ninja, whose responsibility it is to replace components the day before they they break, anticipate obscure printer errors that could bring ruin to the marketing department, repair desktops while their users are out for a cup of coffee, and arrive silently in an employee's cube before they hang up the phone. I'm still messing about with the network monitoring system (especially the TAP gateway, which fails silently half the time), but my official job is now within the realm of support. Working against time on a laptop with a failing hard drive, I'm writing a support web site with the Ruby on Rails framework which will interface with our customer relations management service.
Let me tell you this: Ruby. Is. Amazing.