ClassNotFoundException: java.util.SequencedCollection
Recently I’ve had users of my libraries start reporting mysterious errors due to a missing reference to SequencedCollection, a Java interface added in JDK 21:
Execution error (ClassNotFoundException) at
jdk.internal.loader.BuiltinClassLoader/loadClass (BuiltinClassLoader.java:641).
java.util.SequencedCollection
Why is Jepsen Written in Clojure?
People keep asking why Jepsen is written in Clojure, so I figure it’s worth having a referencable answer. I’ve programmed in something like twenty languages. Why choose a Weird Lisp?
Jepsen is built for testing concurrent systems–mostly databases. Because it tests concurrent systems, the language itself needs good support for concurrency. Clojure’s immutable, persistent data structures make it easier to write correct concurrent programs, and the language and runtime have excellent concurrency support: real threads, promises, futures, atoms, locks, queues, cyclic barriers, all of java.util.concurrent, etc. I also considered languages (like Haskell) with more rigorous control over side effects, but decided that Clojure’s less-dogmatic approach was preferable.
Finding Domains That Send Unactionable Reports in Mastodon
One of the things we struggle with on woof.group is un-actionable reports. For various reasons, most of the reports we handle are for posts that are either appropriately content-warned or don’t require a content warning under our content policy–things like faces, butts, and shirtlessness. We can choose to ignore reports from a domain, but we’d rather not do that: it means we might miss out on important reports that require moderator action. We can also talk to remote instance administrators and ask them to talk to their users about not sending copies of reports to the remote instance if they don’t know what the remote instance policy is, but that’s time consuming, and we only want to do it if there’s an ongoing problem.
I finally broke down and dug around in the data model to figure out how to get statistics on this. If you’re a Mastodon admin and you’d like to figure out which domains send you the most non-actionable reports, you can run this at rails console:
10⁹ Operations: Large Histories with Jepsen
Jepsen is a library for writing tests of concurrent systems: everything from single-node data structures to distributed databases and queues. A key part of this process is recording a history of operations performed during the test. Jepsen checkers analyze a history to find consistency anomalies and to compute performance metrics. Traditionally Jepsen has stored the history in a Clojure vector (an immutable in-memory data structure like an array), and serialized it to disk at the end of the test. This limited Jepsen to histories on the order of tens of millions of operations. It also meant that if Jepsen crashed during a several-hour test run, it was impossible to recover any of the history for analysis. Finally, saving and loading large tests involved long wait times—sometimes upwards of ten minutes.
Over the last year I’ve been working on ways to resolve these problems. Generators are up to ten times faster. A new operation datatype makes each operation smaller and faster to access. Jepsen’s new on-disk format allows us to stream histories incrementally to disk, to work with histories of up to a billion operations far exceeding available memory, to recover safely from crashes, and to load tests almost instantly by deserializing data lazily. New history datatypes support both densely and sparsely indexed histories, and efficiently cache auxiliary indices. They also support lazy disk-backed map and filter. These histories support both linear and concurrent folds, which dramatically improves checker performance on multicore systems: real-world checkers can readily analyze 250,000 operations/sec. Histories support multi-query optimization: when multiple threads fold over the same history, a query planner automatically fuses those folds together to perform them in a single pass. Since Jepsen often folds dozens of times over the same history, this saves a good deal of disk IO and deserialization time. These features are enabled by a new, transactional, dependency-aware task executor.
Fast Multi-Accumulator Reducers
Again with the reductions! I keep writing code which reduces over a collection, keeping track of more than one variable. For instance, here’s one way to find the mean of a collection of integers:
(defn mean
"A reducer to find the mean of a collection. Accumulators are [sum count] pairs."
([] [0 0])
([[sum count]] (/ sum count))
([[sum count] x]
[(+ sum x) (inc count)]))
This mean function is what Clojure calls a reducer, or a reducing function. With no arguments, it constructs a fresh accumulator. With two arguments, it combines an element of some collection with the accumulator, returning a new accumulator. With one argument, it transforms the accumulator into some final result.
Loopr: A Loop/Reduction Macro for Clojure
I write a lot of reductions: loops that combine every element from a collection in some way. For example, summing a vector of integers:
(reduce (fn [sum x] (+ sum x)) 0 [1 2 3])
; => 6
If you’re not familiar with Clojure’s reduce, it takes a reducing function f, an initial accumulator init, and a collection xs. It then invokes (f init x0) where x0 is the first element in xs. f returns a new accumulator value acc1, which is then passed to (f acc1 x1) to produce a new accumulator acc2, and so on until every x in xs is folded into the accumulator. That accumulator is the return value of reduce.
In writing reductions, there are some problems that I run into over and over. For example, what if you want to find the mean of some numbers in a single pass? You need two accumulator variables–a sum and a count. The usual answer to this is to make the accumulator a vector tuple. Destructuring bind makes this… not totally awful, but a little awkward:
(reduce (fn [[sum count] x]
[(+ sum x) (inc count)])
[0 0]
[1 2 3 4 5 6 7])
; => [28 7]
Unifying the Technical Interview
Previously: Rewriting the Technical Interview.
Aisha’s hands rattle you. They float gently in front of her shoulders, wrists cocked back. One sways cheerfully as she banters with the hiring manager—her lacquered nails a cyan mosaic over ochre palms. They flit, then hover momentarily as the two women arrange lunch. When the door closes, Aisha slaps her fingertips eagerly on the pine-veneer tabletop. Where have you seen them before?
Rewriting the Technical Interview
Previously: Typing the Technical Interview.
Update, November 2023: here are the full term rewrite and language macros which formed the seed of this story. These files include OO notation as well as the basic Algol syntax shown here. There is also a sketch of an object-oriented language with classes and inheritance, implemented as a Clojure macro. I do not remember writing it. It looks terrifying.
Clojure from the ground up: polymorphism
Previously: Debugging.
In this chapter, we’ll discuss some of Clojure’s mechanisms for polymorphism: writing programs that do different things depending on what kind of inputs they receive. We’ll show ways to write open functions, which can be extended to new conditions later on, without changing their original definitions. Along the way, we’ll investigate Clojure’s type system in more detail–discussing interfaces, protocols, how to construct our own datatypes, and the relationships between types which let us write flexible programs.
Typing the technical interview
Previously: Hexing the technical interview.
In the formless days, long before the rise of the Church, all spells were woven of pure causality, all actions were permitted, and death was common. Many witches were disfigured by their magicks, found crumpled at the center of a circle of twisted, glass-eaten trees, and stones which burned unceasing in the pooling water; some disappeared entirely, or wandered along the ridgetops: feet never touching earth, breath never warming air.
Hexing the technical interview
Previously: Reversing the technical interview.
Long ago, on Svalbard, when you were a young witch of forty-three, your mother took your unscarred wrists in her hands, and spoke:
Reversing the technical interview
If you want to get a job as a software witch, you’re going to have to pass a whiteboard interview. We all do them, as engineers–often as a part of our morning ritual, along with arranging a beautiful grid of xterms across the astral plane, and compulsively running ls in every nearby directory–just in case things have shifted during the night–the incorporeal equivalent of rummaging through that drawer in the back of the kitchen where we stash odd flanges, screwdrivers, and the strangely specific plastic bits: the accessories, those long-estranged black sheep of the families of our household appliances, their original purpose now forgotten, perhaps never known, but which we are bound to care for nonetheless. I’d like to walk you through a common interview question: reversing a linked list.
First, we need a linked list. Clear your workspace of unwanted xterms, sprinkle salt into the protective form of two parentheses, and recurse. Summon a list from the void.
Serializability, linearizability, and locality
In Herlihy and Wing’s seminal paper introducing linearizability, they mention an important advantage of this consistency model:
Unlike alternative correctness conditions such as sequential consistency [31] or serializability [40], linearizability is a local property: a system is linearizable if each individual object is linearizable.
Locality is important because it allows concurrent systems to be designed and constructed in a modular fashion; linearizable objects can be implemented, verified, and executed independently. A concurrent system based on a nonlocal correctness property must either rely on a centralized scheduler for all objects, or else satisfy additional constraints placed on objects to ensure that they follow compatible scheduling protocols.
Jepsen: VoltDB 6.3
In the last Jepsen post, we found that RethinkDB could lose data when a network partition occurred during cluster reconfiguration. In this analysis, we’ll show that although VoltDB 6.3 claims strict serializability, internal optimizations and bugs lead to stale reads, dirty reads, and even lost updates; fixes are now available in version 6.4. This work was funded by VoltDB, and conducted in accordance with the Jepsen ethics policy.
VoltDB is a distributed SQL database intended for high-throughput transactional workloads on datasets which fit entirely in memory. All data is stored in RAM, but backed by periodic disk snapshots and an on-disk recovery log for crash durability. Data is replicated to at least k+1 nodes to tolerate k failures. Tables may be replicated to every node for fast local reads, or sharded for linear storage scalability.
Jepsen: Crate 0.54.9 version divergence
In the last Jepsen analysis, we saw that RethinkDB 2.2.3 could encounter spectacular failure modes due to cluster reconfiguration during a partition. In this analysis, we’ll talk about Crate, and find out just how many versions a row’s version identifies.
Crate is a shared-nothing, “infinitely scalable”, eventually-consistent SQL database built on Elasticsearch.
Builders vs option maps
I like builders and have written APIs that provide builder patterns, but I really prefer option maps where the language makes it possible. Instead of a builder like
Wizard wiz = new WizardBuilder("some string")
.withPriority(1)
.withMode(SOME_ENUM)
.enableFoo()
.disableBar()
.build();
Returning self or void suggests mutability
So there’s a blog post that advises every method should, when possible, return self. I’d like to suggest you do the opposite: wherever possible, return something other than self.
Mutation is hard
Clojure from the ground up: debugging
Previously: Modeling.
Writing software can be an exercise in frustration. Useless error messages, difficult-to-reproduce bugs, missing stacktrace information, obscure functions without documentation, and unmaintained libraries all stand in our way. As software engineers, our most useful skill isn’t so much knowing how to solve a problem as knowing how to explore a problem that we haven’t seen before. Experience is important, but even experienced engineers face unfamiliar bugs every day. When a problem doesn’t bear a resemblance to anything we’ve seen before, we fall back on general cognitive strategies to explore–and ultimately solve–the problem.
Computational techniques in Knossos
Earlier versions of Jepsen found glaring inconsistencies, but missed subtle ones. In particular, Jepsen was not well equipped to distinguish linearizable systems from sequentially or causally consistent ones. When people asked me to analyze systems which claimed to be linearizable, Jepsen could rule out obvious classes of behavior, like dropping writes, but couldn’t tell us much more than that. Since users and vendors are starting to rely on Jepsen as a basic check on correctness, it’s important that Jepsen be able to identify true linearization errors.
Strong consistency models
Update, 2018-08-24: For a more complete, formal discussion of consistency models, see jepsen.io.
Network partitions are going to happen. Switches, NICs, host hardware, operating systems, disks, virtualization layers, and language runtimes, not to mention program semantics themselves, all conspire to delay, drop, duplicate, or reorder our messages. In an uncertain world, we want our software to maintain some sense of intuitive correctness.
Clojure from the ground up: modeling
Previously: Logistics
Until this point in the book, we’ve dealt primarily in specific details: what an expression is, how math works, which functions apply to different data structures, and where code lives. But programming, like speaking a language, painting landscapes, or designing turbines, is about more than the nuts and bolts of the trade. It’s knowing how to combine those parts into a cohesive whole–and this is a skill which is difficult to describe formally. In this part of the book, I’d like to work with you on an integrative tour of one particular problem: modeling a rocket in flight.
Clojure from the ground up: logistics
Previously, we covered state and mutability.
Up until now, we’ve been programming primarily at the REPL. However, the REPL is a limited tool. While it lets us explore a problem interactively, that interactivity comes at a cost: changing an expression requires retyping the entire thing, editing multi-line expressions is awkward, and our work vanishes when we restart the REPL–so we can’t share our programs with others, or run them again later. Moreover, programs in the REPL are hard to organize. To solve large problems, we need a way of writing programs durably–so they can be read and evaluated later.
Jepsen: Redis redux
In a recent blog post, antirez detailed a new operation in Redis: WAIT. WAIT is proposed as an enhancement to Redis’ replication protocol to reduce the window of data loss in replicated Redis systems; clients can block awaiting acknowledgement of a write to a given number of nodes (or time out if the given threshold is not met). The theory here is that positive acknowledgement of a write to a majority of nodes guarantees that write will be visible in all future states of the system.
As I explained earlier, any asynchronously replicated system with primary-secondary failover allows data loss. Optional synchronous replication, antirez proposes, should make it possible for Redis to provide strong consistency for those operations.
Clojure from the ground up: state
Previously: Macros.
Most programs encompass change. People grow up, leave town, fall in love, and take new names. Engines burn through fuel while their parts wear out, and new ones are swapped in. Forests burn down and their logs become nurseries for new trees. Despite these changes, we say “She’s still Nguyen”, “That’s my motorcycle”, “The same woods I hiked through as a child.”
Clojure from the ground up: macros
In Chapter 1, I asserted that the grammar of Lisp is uniform: every expression is a list, beginning with a verb, and followed by some arguments. Evaluation proceeds from left to right, and every element of the list must be evaluated before evaluating the list itself. Yet we just saw, at the end of Sequences, an expression which seemed to violate these rules.
Clearly, this is not the whole story.
Clojure from the ground up: sequences
In Chapter 3, we discovered functions as a way to abstract expressions; to rephrase a particular computation with some parts missing. We used functions to transform a single value. But what if we want to apply a function to more than one value at once? What about sequences?
For example, we know that (inc 2) increments the number 2. What if we wanted to increment every number in the vector [1 2 3], producing [2 3 4]?
Clojure from the ground up: functions
We left off last chapter with a question: what are verbs, anyway? When you evaluate (type :mary-poppins), what really happens?
user=> (type :mary-poppins)
clojure.lang.Keyword
Clojure from the ground up: basic types
We’ve learned the basics of Clojure’s syntax and evaluation model. Now we’ll take a tour of the basic nouns in the language.
Types
Clojure from the ground up: welcome
This guide aims to introduce newcomers and experienced programmers alike to the beauty of functional programming, starting with the simplest building blocks of software. You’ll need a computer, basic proficiency in the command line, a text editor, and an internet connection. By the end of this series, you’ll have a thorough command of the Clojure programming language.
Who is this guide for?
Jepsen: Strangeloop Hangout
Since the Strangeloop talks won’t be available for a few months, I recorded a new version of the talk as a Google Hangout.
Jepsen: Cassandra
Previously on Jepsen, we learned about Kafka’s proposed replication design.
Cassandra is a Dynamo system; like Riak, it divides a hash ring into a several chunks, and keeps N replicas of each chunk on different nodes. It uses tunable quorums, hinted handoff, and active anti-entropy to keep replicas up to date. Unlike the Dynamo paper and some of its peers, Cassandra eschews vector clocks in favor of a pure last-write-wins approach.
Jepsen: Kafka
In the last Jepsen post, we learned about NuoDB. Now it’s time to switch gears and discuss Kafka. Up next: Cassandra.
Kafka is a messaging system which provides an immutable, linearizable, sharded log of messages. Throughput and storage capacity scale linearly with nodes, and thanks to some impressive engineering tricks, Kafka can push astonishingly high volume through each node; often saturating disk, network, or both. Consumers use Zookeeper to coordinate their reads over the message log, providing efficient at-least-once delivery–and some other nice properties, like replayability.
Jepsen: NuoDB
Previously on Jepsen, we explored Zookeeper. Next up: Kafka.
NuoDB came to my attention through an amazing mailing list thread by the famous database engineer Jim Starkey, in which he argues that he has disproved the CAP theorem:
Jepsen: Zookeeper
In this Jepsen post, we’ll explore Zookeeper. Up next: NuoDB.
Update 2019-07-23: @insumity explains that ZooKeeper sync+read is not, in fact, linearizable–there are conditions under which it might return stale reads.
Jepsen: Postgres
Previously on Jepsen, we introduced the problem of network partitions. Here, we demonstrate that a few transactions which “fail” during the start of a partition may have actually succeeded.
Postgresql is a terrific open-source relational database. It offers a variety of consistency guarantees, from read uncommitted to serializable. Because Postgres only accepts writes on a single primary node, we think of it as a CP system in the sense of the CAP theorem. If a partition occurs and you can’t talk to the server, the system is unavailable. Because transactions are ACID, we’re always consistent.
Riemann 0.2.0
Riemann 0.2.0 is ready. There’s so much left that I want to build, but this release includes a ton of changes that should improve usability for everyone, and I’m excited to announce its release.
Version 0.2.0 is a fairly major improvement in Riemann’s performance and capabilities. Many things have been solidified, expanded, or tuned, and there are a few completely new ideas as well. There are a few minor API changes, mostly to internal structure–but a few streams are involved as well. Most functions will continue to work normally, but log a deprecation notice when used.
65K messages/sec
The Netty redesign of riemann-java-client made it possible to expose an end-to-end asynchronous API for writes, which has a dramatic improvement on messages with a small number of events. By introducing a small queue of pipelined write promises, riemann-clojure-client can now push 65K events per second, as individual messages, over a single TCP socket. Works out to about 120 mbps of sustained traffic.

Timelike 2: everything fails all the time
In the previous post, I described an approximation of Heroku’s Bamboo routing stack, based on their blog posts. Hacker News, as usual, is outraged that the difficulty of building fast, reliable distributed systems could prevent Heroku from building a magically optimal architecture. Coda Hale quips:
Really enjoying @RapGenius’s latest mix tape, “I Have No Idea How Distributed Systems Work”.
Timelike: a network simulator
For more on Timelike and routing simulation, check out part 2 of this article: everything fails all the time. There’s also more discussion on Reddit.
RapGenius is upset about Heroku’s routing infrastructure. RapGenius, like many web sites, uses Rails, and Rails is notoriously difficult to operate in a multithreaded environment. Heroku operates at large scale, and made engineering tradeoffs which gave rise to high latencies–latencies with adverse effects on customers. I’d like to explore why Heroku’s Bamboo architecture behaves this way, and help readers reason about their own network infrastructure.
A typical Riemann contract
I’m not a big fan of legal documents. I just don’t have the resources or ability to reasonably defend myself from a lawsuit; retaining a lawyer for a dozen hours would literally bankrupt me. Even if I were able to defend myself against legal challenge, standard contracts for software consulting are absurd. Here’s a section I encounter frequently:
Ownership of Work Product. All Work Product (as defined below) and benefits thereof shall immediately and automatically be the sole and absolute property of Company, and Company shall own all Work Product developed pursuant to this Agreement.
“Work Product” means each invention, modification, discovery, design, development, improvement, process, software program, work of authorship, documentation, formula, data, technique, know-how, secret or intellectual property right whatsoever or any interest therein (whether or not patentable or registrable under copyright or similar statutes or subject to analogous protection) that is made, conceived, discovered, or reduced to practice by Contractor (either alone or with others) and that (i) relates to Company’s business or any customer of or supplier to Company or any of the products or services being developed, manufactured or sold by Company or which may be used in relation therewith, (ii) results from the services performed by Contractor for Company or (iii) results from the use of premises or personal property (whether tangible or intangible) owned, leased or contracted for by Company.
Blathering about Riemann consistency
tl;dr Riemann is a monitoring system, so it emphasizes liveness over safety.
Riemann is aimed at high-throughput (millions of events/sec/node), partial-harvest event processing, where it is acceptable to trade completeness for throughput at low latencies. For instance, it’s probably fine to drop half of your request latency events on the floor, if you’re calculating a lossy histogram with sampling anyway. It’s also typically acceptable to have nondeterministic behavior with respect to time windows: if one node’s clock is skewed, it’s better to process it “soonish” rather than waiting an unbounded amount of time for it to check in.
Reaching 200K events/sec
I’ve been doing a lot of performance tuning in Riemann recently, especially in the clients–but I’d like to share a particularly spectacular improvement from yesterday.
The Riemann protocol
Language Power
I’ve had two observations floating around in my head, looking for a way to connect with each other.
Many “architecture patterns” are scar tissue around the absence of higher-level language features.
Pipelining requests
I’ve been putting more work into riemann-java-client recently, since it’s definitely the bottleneck in performance testing Riemann itself. The existing RiemannTcpClient and RiemannRetryingTcpClient were threadsafe, but almost fully mutexed; using one essentially serialized all threads behind the client itself. For write-heavy workloads, I wanted to do better.
There are two logical optimizations I can make, in addition to choosing careful data structures, mucking with socket options, etc. The first is to bundle multiple events into a single Message, which the API supports. However, your code may not be structured in a way to efficiently bundle events, so where higher latencies are OK, the client can maintain a buffer of outbound events and flush it regularly.
Core language concepts
Computer languages, like human languages, come in many forms. This post aims to give an overview of the most common programming ideas. It’s meant to be read as one is learning a particular programming language, to help understand your experience in a more general context. I’m writing for conceptual learners, who delight in the underlying structure and rules of a system.
Many of these concepts have varying (and conflicting) names. I’ve tried to include alternates wherever possible, so you can search this post when you run into an unfamiliar word.
Getting started in software
A good friend of mine from college has started teaching himself to code. He’s hoping to find a job at a Bay Area startup, and asked for some help getting oriented. I started writing a response, and it got a little out of hand. Figure this might be of interest for somebody else on this path. :)
I want to give you a larger context around how this field works–there’s a ton of good documentation on accomplishing specifics, but it’s hard to know how it fits together, sometimes. Might be interesting for you to skim this before we meet tomorrow, so some of the concepts will be familiar.
Schadenfreude
Schadenfreude is a benchmarking tool I’m using to improve Riemann. Here’s a profile generated by the new riemann-bench, comparing a few recent releases in their single-threaded TCP server throughput. These results are dominated by loopback read latency–maxing out at about 8-9 kiloevents/sec. I’ll be using schadenfreude to improve client performance in high-volume and multicore scenarios.

A Clojure benchmarking thing
I needed a tool to evaluate internal and network benchmarks of Riemann, to ask questions like
- Is parser function A or B more efficient?
- How many threads should I allocate to the worker threadpool?
- How did commit 2556 impact the latency distribution?
Riemann 0.1.3
Ready? Grab the tarball or deb from http://aphyr.github.com/riemann/
0.1.3 is a consolidation release, comprising 2812 insertions and 1425 deletions. It includes numerous bugfixes, performance improvements, features–especially integration with third-party tools–and clearer code. This release includes the work of dozens of contributors over the past few months, who pointed out bugs, cleaned up documentation, smoothed over rough spots in the codebase, and added whole new features. I can’t say thank you enough, to everyone who sent me pull requests, talked through designs, or just asked for help. You guys rock!
The Future of Riemann
For the last three years Riemann (and its predecessors) has been a side project: I sketched designs, wrote code, tested features, and supported the community through nights and weekends. I was lucky to have supportive employers which allowed me to write new features for Riemann as we needed them. And yet, I’ve fallen behind.
Dozens of people have asked for sensible, achievable Riemann improvements that would help them monitor their systems, and I have a long list of my own. In the next year or two I’d like to build:
Burn the Library

Write contention occurs when two people try to update the same piece of data at the same time.
Cheerleading
In response to Results of the 2012 State of Clojure Survey:
The idea of having a primary language honestly comes off to me as a sign that the developer hasn't spent much time programming yet: the real world has so many languages in it, and many times the practical choice is constrained by that of the platform or existing code to interoperate with.
Context switches and serialization in Node
More from Hacker News. I figure this might be of interest to folks working on parallel systems. I’ll let KirinDave kick us off with:
Go scales quite well across multiple cores iff you decompose the problem in a way that's amenable to Go's strategy. Same with Erlang.No one is making “excuses”. It’s important to understand these problems. Not understanding concurrency, parallelism, their relationship, and Amdahl’s Law is what has Node.js in such trouble right now.
What is concurrency?
This is a response to a Hacker News thread asking about concurrency vs parallelism.
Concurrency is more than decomposition, and more subtle than “different pieces running simultaneously.” It’s actually about causality.
Configuration and scope
Most applications have configuration: how to open a connection to the database, what file to log to, the locations of key data files, etc.
Configuration is hard to express correctly. It’s dynamic because you don’t know the configuration at compile time–instead it comes from a file, the network, command arguments, etc. Config is almost always implicit, because it affects your functions without being passed in as an explicit parameter. Most languages address this in two ways:
Riemann Recap: Client Libraries and Performance
I’ve been focusing on Riemann client libraries and optimizations recently, both at Boundary and on my own time.
Boundary uses the JVM extensively, and takes advantage of Coda Hale’s Metrics. For our applications I’ve written a Riemann Java UDP and TCP client, which also includes a Metrics reporter. The Metrics reporter (I’ll be submitting that to metrics-contrib later) will just send periodic events for each of the metrics in a registry, and optionally some VM statistics as well. It can prefix each service, filter with predicates, and has been reporting for two of our production systems for about a week now.
Riemann 0.1.0
The initial stable release of Riemann 0.1.0 is available for download. This is the culmination of the 0.0.3 development path and 2 months of production use at Showyou.
Is it production ready? I think so. The fundamental stream operators are in place. A comprehensive test suite checks out. Riemann has never crashed. Its performance characteristics should be suitable for a broad range of scales and applications.
Riemann: Breaking the 10k barrier
When I designed UState, I had a goal of a thousand state transitions per second. I hit about six hundred on my Macbook Pro, and skirted 1000/s on real hardware. Eventmachine is good, but I started to bump up against concurrency limits in MRI’s interpreter lock, my ability to generate and exchange SQL with SQLite, and protobuf parse times. So I set out to write a faster server. I chose Clojure for its expressiveness and powerful model of concurrent state–and more importantly, the JVM, which gets me Netty, a mature virtual machine with a decent thread model, and a wealth of fast libraries for parsing, state, and statistics. That project is called Riemann.
Today, I’m pleased to announce that Riemann crossed the 10,000 event/second mark in production. In fact it’s skirting 11k in my stress tests. (That final drop in throughput is an artifact of the graph system showing partially-complete data.)
It Boggles the Mind
Microsoft released this little gem today, fixing a bug which allowed remote code execution on all Windows Vista, 6, and Server 2008 versions.
...allow remote code execution if an attacker sends a continuous flow of specially crafted UDP packets to a closed port on a target system.


Do not expose Riak to the internet
Major thanks to John Muellerleile (@jrecursive) for his help in crafting this.
Actually, don’t expose pretty much any database directly to untrusted connections. You’re begging for denial-of-service issues; even if the operations are semantically valid, they’re running on a physical substrate with real limits.
Riak-pipe mapreduce
As a part of the exciting series of events (long story…) around our riak cluster this week, we switched over to riak-pipe mapreduce. Usually, when a node is down mapreduce times shoot through the roof, which causes slow behavior and even timeouts on the API. Riak-pipe changes that: our API latency for mapreduce-heavy requests like feeds and comments fell from 3-7 seconds to a stable 600ms. Still high, but at least tolerable.

Oracle, on NoSQL
Do you really want to be contributing to an open source effort? ... Don't be risking your data on NoSQL databases.
Says the company which is scheduling talks around Oracle NoSQL at its OpenWorld conference.
Systems Security: A Primer
The riak-users list receives regular questions about how to secure a Riak cluster. This is an overview of the security problem, and some general techniques to approach it.
Theory
It's always DNS's fault
One of the hard-won lessons of the last few weeks has been that inexplicable periodic latency jumps in network services should be met with an investigation into named.

Scaling at Showyou
John Mullerleile, Phil Kulak, and I gave a talk tonight, entitled “Scaling at Showyou.”

Unsafe thread concurrency with fork
AWS::S3 is not threadsafe. Hell, it’s not even reusable; most methods go through a class constant. To use it in threaded code, it’s necessary to isolate S3 operations in memory. Fork to the rescue!
def s3(key, data, bucket, opts)
begin
fork_to do
AWS::S3::Base.establish_connection!(
:access_key_id => KEY,
:secret_access_key => SECRET
)
AWS::S3::S3Object.store key, data, bucket, opts
end
rescue Timeout::Error
raise SubprocessTimedOut
end
end
def fork_to(timeout = 4)
r, w, pid = nil, nil, nil
begin
# Open pipe
r, w = IO.pipe
# Start subprocess
pid = fork do
# Child
begin
r.close
val = begin
Timeout.timeout(timeout) do
# Run block
yield
end
rescue Exception => e
e
end
w.write Marshal.dump val
w.close
ensure
# YOU SHALL NOT PASS
# Skip at_exit handlers.
exit!
end
end
# Parent
w.close
Timeout.timeout(timeout) do
# Read value from pipe
begin
val = Marshal.load r.read
rescue ArgumentError => e
# Marshal data too short
# Subprocess likely exited without writing.
raise Timeout::Error
end
# Return or raise value from subprocess.
case val
when Exception
raise val
else
return val
end
end
ensure
if pid
Process.kill "TERM", pid rescue nil
Process.kill "KILL", pid rescue nil
Process.waitpid pid rescue nil
end
r.close rescue nil
w.close rescue nil
end
end
Lesser known leader election algorithms
In distributed systems, one frequently needs a set of n nodes to come to a consensus on a particular coordinating or master node, referred to as the leader. Leader election protocols are used to establish this. Sure, you could do the Swedish or the Silverback, but there’s a whole world of consensus algorithms out there. For instance:
{kind=link}
The Agent Smith
Zlib unzip without header or CRC checks
If you ever need to unzip data compressed with zlib without a header (e.g. produced by Erlang’s zlib:zip), it pays to be aware that
windowBits can also be -8..-15 for raw inflate. In this case, -windowBits determines the window size. inflate() will then process raw deflate data, not looking for a zlib or gzip header, not generating a check value, and not looking for any check values for comparison at the end of the stream. (zlib.h)
Erlang tattoo
23:09 < justin> Erlang tattoo might be cool
23:09 < justin> not many have those
23:10 < justin> not even sure what that would look like
23:10 < aphyr_> Yeah, really gonna add to my aura of mysterious sexiness
23:10 < aphyr_> "What's that?"
23:10 < aphyr_> "Oh, that's Erlang. It's a distributed functional programming language."
23:10 < justin> Mad tail
23:10 < aphyr_> "Tell me, would you and your friends like to do it... concurrently?"
23:13 < aphyr_> "Oh sorry. You're not my... TYPE."
23:13 < aphyr_> DAMN YOOOOUUU STATIC COMPILERS!
Things are getting a little slap-happy here in the final hours before Showyou launch.
SSH to your stolen laptop
A holiday present for Hacker News (and you too!): tund, a daemon to automatically maintain reverse SSH tunnels. If your laptop gets stolen, and the thief connects it to the internet, tund will reach out and establish an SSH tunnel from somewhere.com to itself. That means you can log into it, even if it’s behind a firewall or NAT.
I also use it to log into my home computer from work.
Vodpod Chrome Extension
I just built a Chrome extension for Vodpod.com. It builds off of the high-performance API I wrote last year, and offers some pretty sweet unread-message synchronization. You’ll get desktop notifications when someone you know collects a video, in addition to a miniature version of your feed.
As it turns out, Chrome is really great to develop for. Everything just works, and it works pretty much like the standard says it should. Local storage, JSON, inter-view communication, notifications… all dead simple. Props to the Chrome/Chromium teams!
Installing the Android SDK for Eclipse
Here’s the quickest way I know to get Eclipse up and running with the Android SDK plugin. To install each of these packages, go to Help->Install New Software, add the given URI as a package source, and install the given package. Eclipse may prompt you to restart after some installs.
| Source | Package |
|---|---|
| http://download.eclipse.org/tools/gef/updates/releases/ | GEF SDK |
| http://download.eclipse.org/modeling/emf/updates/releases/ | EMF SDK 2.5.0 (EMF + XSD) |
| http://download.eclipse.org/webtools/updates | Web Tools Platform / Eclipse XML Editors and Tools |
| https://dl-ssl.google.com/android/eclipse/ | Developer Tools |
Debugging the Droid on Ubuntu Karmic
$ adb devices
List of devices attached
???????????? no permissions
A few things have changed since the Android docs were written. If you want to talk to your Motorola Droid via ADB in Ubuntu 9.10 Karmic, I recommend the following udev rule.
Yamr: A Linux Yammer Client
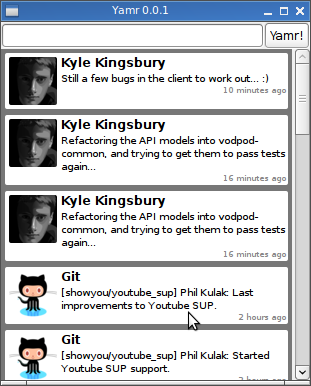
Sometime in the last couple of weeks, the Yammer AIR client stopped fetching new messages. I’ve grown to really like the service, especially since it delivers a running stream of commits to the Git repos I’m interested in, so I broke down and wrote my own client.
Cortex Reaver 0.2.0 Released
All right boys and girls, I’m all for quality releases and everything, but Cortex Reaver 0.2.0 is raring to go. Just gem upgrade to get some awesome blogging goodness.
Autotags
I threw together a little jQuery tag editor last weekend for Cortex Reaver, since hours of google searching turned up, well, not much. Feel free to try the demo and use it for your projects.
New Vodpod API Bindings
I re-wrote the Ruby Vodpod bindings for the new API I’ve been writing. It’s available as a gem:
cr:codegem install vodpod</cr:code>
RSSCloud Callbacks to a Different IP
A bit of context, in case you haven’t been keeping up with the real-time web craze:
RSSCloud is an… idea* for getting updates on RSS feeds to clients faster, while decreasing network load. In traditional RSS models, subscribers make an HTTP request every 10 minutes or so to a publisher to check for updates. In RSSCloud, a cloud server aggregates several feeds from authors. When feeds are changed, their authors send an HTTP request to the cloud server notifying them of the update. The cloud server contacts one or more subscribers of the feed, sending them a notice that the feed has changed. The subscribers then request the feed from the authors. Everyone gets their updates faster, and with fewer requests across the network.
Fun With PHP Arrays
Reading the PHP documentation has convinced me (again) of what a mind-bogglingly broken language this is. Quickly, see if you can predict this behavior:
<cr:code lang=“php”>
Construct 0.1.3
I released version 0.1.3 of Construct today. It incorporates a few bugfixes for nested schemas, and should be fit for general use.
Construct: Ruby Configuration
I got tired of writing configuration classes for everything I do, and packaged it all up in a tiny gem: Construct.
Highlights
Ruby Vodpod Bindings
I recently wrote some quick and dirty Ruby bindings for the Vodpod API. They’re pretty rough right now, but usable.
Firefox Memory Leak of Doom
A few minutes ago, I realized my disk was paging when I ran Vim. Took a quick look at gkrellm, and yes, in fact, I was almost out of swap space, and physical memory was maxed out. The culprit was Firefox, as usual; firefox-bin was responsible for roughly a gigabyte of X pixmap memory.
So I spent some time digging, and realized that I’d had a window open to the Nagios status map for a few hours, which includes a 992 x 1021 pixel PNG. The page refreshes every minute or so. So I closed Firefox, brought up xrestop, opened the status map again, and watched. Sure enough, X pixmap usage for Firefox jumped up by about 2500K per refresh. In the last 10 minutes or so, that number has ballooned to roughly 50MB.
OpenOffice.org 2.0 and GTK
I run Fluxbox as my primary window manager, and use gnome-settings-daemon to keep gnome apps happy and GTK-informed. Thus far, all has gone well. However, OpenOffice.org does something very funky to determine whether one is using KDE or GTK, finds neither on my system, and drops back to the horribly ugly interface of 1997.
I haven't figured out how to fix this yet, but running gnome-session sets up something which convinces OpenOffice to use the GTK theme. It doesn't appear to be an environment variable, because I can set my environment identically under gnome and fluxbox, with no difference in OO behavior. My guess is there's some sort of socket or temporary file set by gnome-session, but it's all a mystery and the source is obfuscated. If anyone knows of a way to force OpenOffice 2.0 to use GTK, I'd be interested to hear about it.
Fun with ALSA
I just realized that aside from simple copies, the ALSA route_policy duplicate will mix to arbitrary numbers of output channels AND that such a device can use a Dmix PCM device as its slave. This means that it's possible to take 2 channel CD audio and have it mixed to 5.1 channel surround, and still let other applications use the sound card. This makes XMMS very happy.
On the other hand, my onboard i810 sound card reverses the surround and center channels, and it does some funky mixing on the center channel for the subwoofer, which sounds really messed up when played on the rear speakers. I haven't figured out how to compensate for this yet.
SBLD Statistics
I wrote a quick script to analyze the logs generated by SBLD. You can pull them out of syslog, or (as I'm doing), have your log checker aggregate SBLD events for you. I'm making the statistics for my site available here, as a resource for others.
SBLD - The SSH Blacklist Daemon
If you run a server with SSHD exposed to the internet, chances are that server is being scanned for common username and password combinations. These often appear in the authorization log (/var/log/auth.log) as entries like:
cr:code
Jun 12 13:33:57 localhost sshd[18900]: Illegal user admin from 219.254.25.100
Jun 12 13:37:17 localhost sshd[18904]: Illegal user admin from 219.254.25.100
Jun 12 13:37:20 localhost sshd[18906]: Illegal user test from 219.254.25.100
Jun 12 13:37:22 localhost sshd[18908]: Illegal user guest from 219.254.25.100
</cr:code>